
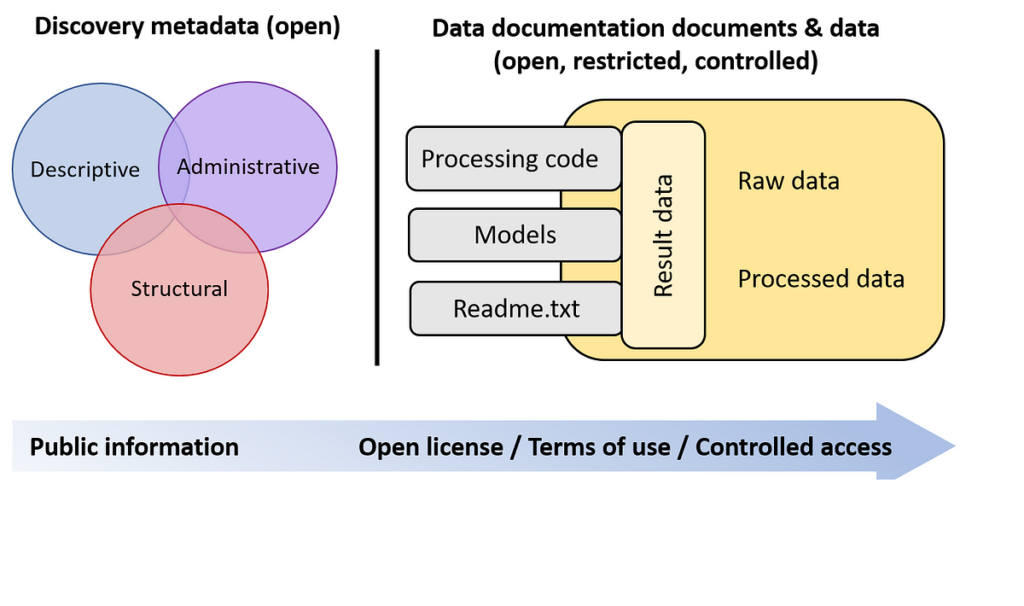
Introduction
Data documentation, an integral process in managing and understanding data, refers to the practice of accompanying data with relevant information — metadata — that explains its origin, structure, context, and specifications. In today’s information-driven world, the importance of data documentation cannot be overstated, as it ensures the accuracy, reliability, and utility of data across various fields. This essay posits that effective data documentation is essential for accurate data analysis, replication of research findings, and ensuring data longevity and usability.

Data is like a puzzle; documentation is the guide that helps piece it together.
The Necessity of Data Documentation
- Research Integrity: Data documentation is a cornerstone of research integrity. It enables researchers to replicate studies and verify results, ensuring the reliability of scientific findings. Proper documentation provides a roadmap for understanding the data’s context, methods of collection, and limitations.
- Data Analysis: In data analysis, documentation serves as a guide to interpret the data correctly. It helps analysts understand the nuances and specific conditions under which the data was gathered, leading to more accurate and meaningful insights.
- Compliance and Legal Requirements: Various industries are governed by data protection and privacy laws, like the GDPR in Europe, mandating meticulous data documentation. This compliance ensures ethical handling of data, especially sensitive personal information.
Methods and Best Practices in Data Documentation
- Metadata Creation: Creating detailed metadata is a fundamental aspect of data documentation. Metadata should include information about the data’s author, date of creation, source, format, and any changes made over time.
- Standardization: Using standardized formats and protocols ensures that data can be easily understood and used by others. This uniformity is crucial for data sharing and collaborative efforts.
- Tools and Technologies: Various tools and software, like data catalogs and documentation software, are available to assist in the process of data documentation. These tools help in organizing and maintaining data records efficiently.
Challenges in Data Documentation
- Volume and Variety of Data: The sheer volume and diversity of data generated today pose significant challenges in maintaining comprehensive and accurate documentation.
- Keeping Documentation Updated: In fast-paced environments, keeping documentation updated is a challenging task. This is critical as outdated documentation can lead to misinterpretation of data.
- Training and Resources: Effective data documentation requires proper training and adequate resources, which can be a constraint in many organizations.
Case Studies and Examples
- Academic Research: In scientific research, data documentation has played a pivotal role in replicating studies in fields ranging from climate science to medicine, ensuring the validity of groundbreaking discoveries.
- Business Applications: Businesses leverage documented data for strategic decision-making, compliance, and gaining customer insights, which drives growth and innovation.
- Government and Public Data: Data documentation in government sectors enhances transparency and public access to information, fostering trust and informed citizenry.
Benefits of Effective Data Documentation
- Enhanced Data Sharing: Well-documented data fosters a culture of sharing and collaboration, essential in advancing knowledge and innovation across various fields.
- Long-Term Data Preservation: Proper documentation ensures that data remains interpretable and useful over long periods, preserving its historical and scientific value.
- Innovation and Development: Documented data can be a catalyst for innovation and development, providing the foundation for new discoveries and advancements.
Code
Creating a synthetic dataset and providing complete data documentation along with plots in Python involves several steps. We’ll first generate a synthetic dataset, then document it properly, and finally create some plots to visualize the data.
Step 1: Generating a Synthetic Dataset
We’ll use libraries like pandas and numpy to create a synthetic dataset. This dataset can simulate a real-world scenario, like a customer database with fields such as age, income, and purchase category.
Step 2: Data Documentation
Data documentation will involve describing each field in the dataset, its data type, and any assumptions or specific generation rules applied.
Step 3: Data Visualization
We’ll use matplotlib or seaborn for creating plots that provide insights into our dataset, such as distribution of ages, income, and purchase categories.
Let’s start with the code to generate and document a synthetic dataset and then create some basic plots.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# Step 1: Generating a Synthetic Dataset
np.random.seed(0)
n = 1000 # Number of records
ages = np.random.randint(18, 70, size=n)
incomes = np.random.normal(50000, 15000, n).round(2)
purchase_categories = np.random.choice(['Electronics', 'Clothing', 'Groceries', 'Books'], size=n)
df = pd.DataFrame({'Age': ages, 'Income': incomes, 'Purchase_Category': purchase_categories})
# Step 2: Data Documentation
data_documentation = """
Dataset Name: Synthetic Customer Data
Number of Records: 1000
Fields:
- Age: Integer. Represents the age of the customer. Range: 18-70.
- Income: Float. Represents the annual income of the customer in USD. Normally distributed with mean 50000 and std dev 15000.
- Purchase_Category: String. Represents the category of items purchased. Categories: 'Electronics', 'Clothing', 'Groceries', 'Books'.
"""
print(data_documentation)
# Step 3: Data Visualization
# Plotting the distribution of ages
plt.figure(figsize=(10, 6))
sns.histplot(df['Age'], bins=20, kde=True)
plt.title('Age Distribution of Customers')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
# Plotting income distribution
plt.figure(figsize=(10, 6))
sns.histplot(df['Income'], bins=20, kde=True, color='green')
plt.title('Income Distribution of Customers')
plt.xlabel('Income (USD)')
plt.ylabel('Frequency')
plt.show()
# Plotting purchase categories
plt.figure(figsize=(10, 6))
sns.countplot(x='Purchase_Category', data=df)
plt.title('Purchase Category Distribution')
plt.xlabel('Purchase Category')
plt.ylabel('Count')
plt.show()
This code snippet will:
- Create a dataset with 1000 entries containing customer age, income, and purchase category.
- Print out a brief documentation of the dataset, including descriptions of each field.
- Generate plots showing the distributions of age, income, and purchase categories.
Dataset Name: Synthetic Customer Data
Number of Records: 1000
Fields:
- Age: Integer. Represents the age of the customer. Range: 18-70.
- Income: Float. Represents the annual income of the customer in USD. Normally distributed with mean 50000 and std dev 15000.
- Purchase_Category: String. Represents the category of items purchased. Categories: 'Electronics', 'Clothing', 'Groceries', 'Books'.



Remember, this is a basic example. In real-world applications, data documentation can be more complex, involving data sources, collection methods, preprocessing steps, and more.
Conclusion
Data documentation is not merely a procedural task; it is a critical component in the lifecycle of data. This essay has underscored the indispensability of data documentation in ensuring research integrity, facilitating accurate data analysis, and complying with legal standards. As we navigate the complexities of the digital age, the emphasis on and improvement of data documentation practices is not just necessary; it is imperative for the progression and integrity of our data-driven society.





