
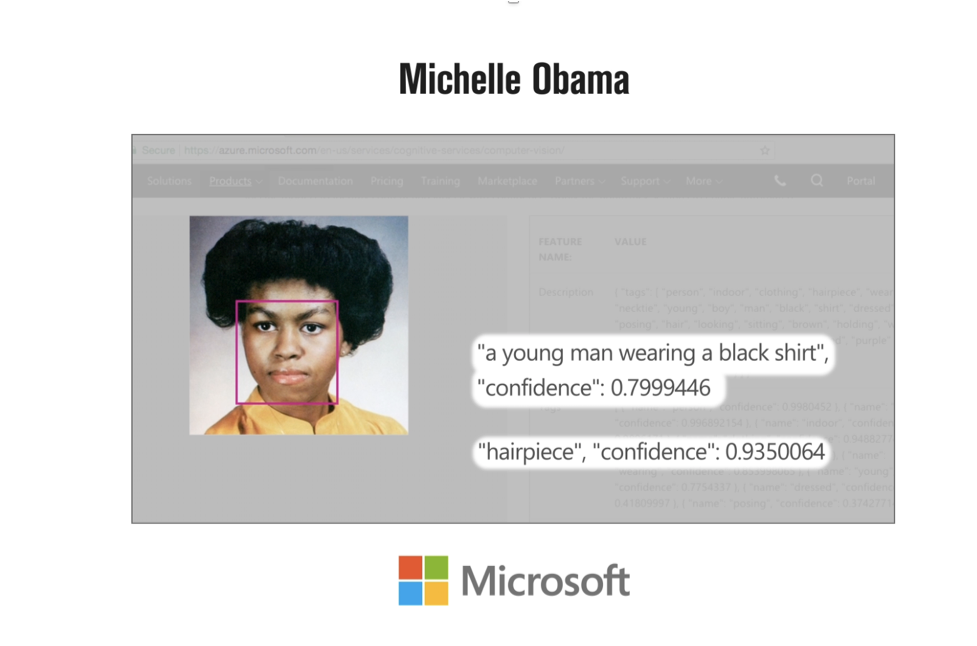

Machine learning algorithms are becoming increasingly integral to our daily lives, impacting decision-making processes in various sectors, from finance and healthcare to hiring and criminal justice systems. While these algorithms promise objectivity and efficiency, they are not immune to the biases ingrained in the data used to train them. One of the most pressing issues facing the field of machine learning is the prevalence of racial bias, which has the potential to perpetuate existing social inequalities and exacerbate systemic discrimination.
Understanding Racial Bias in Machine Learning
Racial bias in machine learning refers to the presence of unfair, prejudiced, or discriminatory decisions made by algorithms that disproportionately affect individuals of certain racial or ethnic backgrounds. These biases emerge because machine learning algorithms learn patterns and associations from historical data, often reflecting the biases present in society. For example, if historical data used to train a hiring algorithm shows a disproportionate underrepresentation of certain racial groups in specific professions, the algorithm might perpetuate this bias by favoring candidates from overrepresented racial backgrounds.
Root Causes of Racial Bias in Machine Learning
Racial bias in machine learning algorithms is a pressing concern that has significant implications for fairness and equity in decision-making processes. Several factors contribute to the emergence and perpetuation of bias in these algorithms.
One of the primary factors is biased training data. Machine learning models heavily rely on historical data to learn patterns and make predictions. If this training data contains historical biases, the algorithms are likely to replicate and perpetuate these biases in their decision-making, potentially leading to discriminatory outcomes.
Another critical factor is the lack of diversity in development teams. Homogeneous development teams may unintentionally overlook biases present in the algorithms they create, reinforcing the blind spots and prejudices of the majority. In contrast, diverse teams with varied perspectives are more likely to identify and address potential biases effectively.

Data collection methods can also introduce biases into machine learning algorithms. Biases may arise due to skewed sampling methods, cultural misunderstandings during data collection, or human prejudices in the labeling process. Such biases can significantly impact the fairness and accuracy of the resulting algorithms. The complexity of machine learning models poses another challenge. Complex models can obscure the decision-making process, making it difficult to identify and address potential biases. As a result, it becomes crucial to develop techniques that enhance the interpretability of these models to understand how they arrive at their conclusions.
The consequences of racial bias in machine learning are far-reaching and can have a profound impact on society. Biased algorithms can reinforce existing inequitable systems, perpetuating social inequalities and further marginalizing disadvantaged racial groups. Moreover, these biased algorithms can lead to discriminatory decision-making in crucial domains such as hiring, lending, and law enforcement, adversely affecting minority communities and reinforcing systemic discrimination.
Furthermore, racial bias in machine learning can erode public trust in technology. When individuals perceive biased algorithms as unfair or discriminatory, they may become skeptical of adopting machine learning solutions, hindering the potential benefits that these technologies can bring.
Addressing racial bias in machine learning requires a multi-faceted approach. Ensuring that training data is diverse and representative of all racial and ethnic backgrounds is essential. This step actively addresses underrepresentation and helps create more equitable algorithms.
Additionally, implementing bias detection and mitigation processes during algorithm development and deployment is crucial. Rigorous testing and validation can help identify and rectify biases before they lead to discriminatory outcomes.
Ethical guidelines should be established and adhered to throughout the entire machine learning lifecycle. These guidelines should encompass data collection, model development, and decision-making processes to promote fairness and accountability.
Striving for transparency in algorithms’ decision-making processes is equally important. When users can understand how these models arrive at their conclusions, it fosters trust and accountability in the technology.
Finally, continuous monitoring of algorithm performance for bias is vital. Regularly assessing and adapting the models ensures that they remain fair and equitable as societal norms and circumstances evolve.
In conclusion, addressing racial bias in machine learning algorithms is crucial for building a more just and equitable future. By recognizing the root causes of bias and implementing comprehensive strategies, we can work towards creating machine learning algorithms that promote fairness, inclusivity, and social good.
As machine learning algorithms continue to infiltrate our daily lives, it is crucial to address and rectify racial bias to build a more equitable and just future. Acknowledging the existence of bias in machine learning is the first step towards creating algorithms that uplift and empower all members of society, regardless of their racial or ethnic background. By fostering diversity, transparency, and ethical practices, we can harness the full potential of machine learning while minimizing the perpetuation of racial biases.





