
Introduction
In the realm of natural language processing and text analysis, EdgeNGram is a powerful technique that holds immense potential. It offers a unique approach to text indexing and search, enabling efficient and accurate retrieval of information from vast amounts of textual data. By breaking down words into smaller components called n-grams, EdgeNGram allows for enhanced text matching and prediction, making it a valuable tool in various domains. This essay delves into the concept of EdgeNGram, its applications, and its significance in modern text analysis.
Understanding EdgeNGram
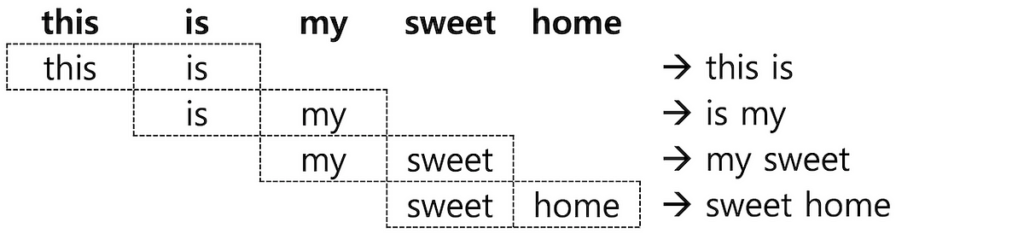
EdgeNGram, also known as character n-gram, is a technique used to transform text into a sequence of contiguous character subsequences. These subsequences, known as n-grams, consist of a fixed number of characters extracted from the original text. The “edge” in EdgeNGram refers to the fact that the n-grams are taken from the beginning or end of each word.
For example, if we consider the word “example” and use a trigram (3-gram) EdgeNGram approach, the resulting n-grams would be “exa,” “exa,” “xam,” “amp,” “mpl,” and “ple.” By breaking down words into these smaller units, EdgeNGram captures more granular information about the structure and content of the text, enabling a variety of useful applications.
Applications of EdgeNGram
- Search Autocomplete and Suggestion: EdgeNGram is commonly employed in search engines to provide autocomplete suggestions as users type their queries. By indexing a large corpus of words using EdgeNGram, search engines can match and predict potential completions based on the characters entered. This feature enhances user experience and improves search accuracy.
- Fuzzy Matching and Spell Checking: EdgeNGram allows for fuzzy matching and spell checking by calculating the similarity between n-grams. It can detect and correct typographical errors, identify similar words, and suggest alternative options. This is particularly useful in applications like online forms, document processing, and data cleaning.
- Entity Recognition and Named Entity Disambiguation: EdgeNGram can assist in entity recognition tasks by capturing partial matches of entities present in a text. It aids in identifying named entities such as names of people, organizations, locations, and more. Additionally, EdgeNGram can be utilized in named entity disambiguation to resolve potential ambiguities by considering partial matches of different entities.
- Natural Language Processing (NLP) Pipelines: In NLP pipelines, EdgeNGram can be utilized as a preprocessing step for feature extraction, allowing for improved downstream tasks such as text classification, sentiment analysis, and topic modeling. By generating n-grams, the model can capture more contextual information, leading to enhanced performance in various NLP applications.
Significance and Benefits
The utilization of EdgeNGram brings several benefits in the field of text analysis:
- Flexibility and Adaptability: EdgeNGram is adaptable to different languages and writing systems, making it a versatile technique for text analysis tasks across diverse linguistic contexts.
- Efficient Indexing: By breaking down words into smaller units, EdgeNGram enables efficient indexing and retrieval of information from large text corpora. It significantly reduces the search space, leading to improved computational performance.
- Robustness to Typos and Misspellings: EdgeNGram’s ability to handle typographical errors and suggest corrections enhances the accuracy of search queries, spell checkers, and information retrieval systems.
- Increased Recall: EdgeNGram’s partial matching capabilities enhance recall by capturing relevant results even when the query or input text contains incomplete or misspelled words.
While EdgeNGram is a powerful technique for text analysis, there are still some open problems and challenges associated with its implementation and usage. Here are a few of them:
- Parameter Selection: The selection of the appropriate value for the n-gram size (n) in EdgeNGram is crucial. Choosing a small value may result in an excessive number of n-grams, leading to increased memory usage and potential information loss. On the other hand, selecting a large value may lead to sparse or less informative n-grams. Determining the optimal n value for a specific task or dataset remains an open problem.
- Contextual Understanding: EdgeNGram treats words as a sequence of character n-grams without considering the context or semantics of the text. While this approach is useful for tasks such as autocomplete and spell checking, it may not capture the full meaning or intent behind a word or phrase. Developing techniques that incorporate contextual understanding within the EdgeNGram framework is an ongoing research area.
- Multilingual Support: EdgeNGram is primarily designed for text analysis in English or languages with similar writing systems. Adapting EdgeNGram to handle languages with different scripts, orthographic rules, or complex character interactions remains an open challenge. Extending its functionality to support a wide range of languages is an area of active research.
- Efficiency with Large Datasets: EdgeNGram’s efficiency diminishes when dealing with large datasets or long words. Generating and indexing all possible n-grams can become computationally expensive and memory-intensive. Developing scalable algorithms and techniques to handle large-scale text analysis with EdgeNGram is an ongoing research area.
- Handling Noisy or Misspelled Text: While EdgeNGram can handle simple typos and misspellings to some extent, it may struggle with more complex errors or noisy text. Improving the robustness of EdgeNGram to handle various types of errors and noisy text inputs is a challenging problem that researchers are actively addressing.
- Evaluating Performance: There is a need for standardized evaluation metrics and benchmarks to measure the performance of EdgeNGram-based models across different text analysis tasks. Defining appropriate evaluation criteria and datasets can help in comparing different approaches and assessing the effectiveness of EdgeNGram in various scenarios.
Addressing these open problems and challenges will further enhance the capabilities and effectiveness of EdgeNGram in text analysis applications, enabling more accurate and context-aware analysis of textual data. Ongoing research and innovation in these areas will contribute to the continuous development and refinement of EdgeNGram techniques.
Code
Here’s an example of how you can implement EdgeNGram in Python using the nltk library:
from nltk import ngramsdef generate_edge_ngrams(word, n):
# Convert the word to lowercase for consistency
word = word.lower()
# Generate the character n-grams using the nltk ngrams function
ngram_list = list(ngrams(word, n))
# Convert the n-grams back to strings
ngram_strings = [''.join(ngram) for ngram in ngram_list]
return ngram_strings
# Example usage
word = "example"
n = 3
edge_ngrams = generate_edge_ngrams(word, n)
print(edge_ngrams)
In this code snippet, we define the generate_edge_ngrams function that takes a word and the value of n as inputs. The function converts the word to lowercase, generates character n-grams using the ngrams function from the nltk library, and converts the resulting n-grams back to strings. Finally, it returns a list of the generated edge n-grams.
['exa', 'xam', 'amp', 'mpl', 'ple']
In the example usage, we set the word variable to “example” and n to 3, indicating that we want to generate trigrams (3-grams) from the word. The code then calls the generate_edge_ngrams function and prints the resulting edge n-grams.
You will need to have the nltk library installed to run this code. If you haven’t installed it yet, you can do so by running pip install nltk in your command line or terminal.
Conclusion
EdgeNGram is a valuable technique in text analysis, offering a unique perspective on textual data by breaking words down into smaller units. Its applications span across a wide range of domains, including search engines, spell checking, entity recognition, and natural language processing pipelines. With its flexibility, efficiency, and robustness, EdgeNGram has proven to be an indispensable tool for unlocking the potential of textual analysis, enabling researchers and developers to extract valuable insights and improve user experiences in the realm of language processing.





