
Machine Learning Models:
Machine learning models can be classified into Supervised and Unsupervised machine learning models.
It involves the series of function that makes the input to output based on a series of example input and output
Example: If we have dataset of two variable one is age as input and other be shoe price as output
We can implement Machine learning model to predict the show size of a person based on age
Types of Supervised Machine Learning:
- Regression
- Classification
In regression model we find the target value based on independent predictor which means we can use this to find the relationship between dependent variable and independent variable
In Regression Model the output is continous
Types of Regression Model:
- Linear Regression:
Linear Regression is simply finding the line that fits data. its extension included multiple linear regression that is finding the place of best fit and polynomial regression, that is finding the curve for best fit.
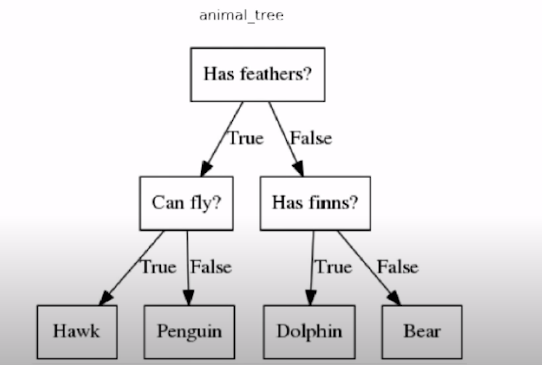
2. Decision Tree:

A decision tree in a regression model is a type of supervised learning algorithm that is used to predict a continuous target variable. It works by recursively partitioning the data into smaller subsets based on the feature that provides the best split, with the goal of minimizing the variance of the target variable within each subset.
The key aspects of a decision tree for regression are:
- Root Node: The top-most node of the tree, which contains the entire dataset.
- Internal Nodes: Nodes that have child nodes, representing a decision based on a feature value.
- Leaf Nodes: The terminal nodes of the tree, which provide the predicted value of the target variable.
The more node we have the more accurate our decision tree will be.
3.Random Forest:
The Random Forest is Ensemble Learning Technique based on decision Tree, that involves creating multiple decision tree using bootstrap dataset of original data randomly selecting a subset of variable and each step of decision tree.
The model select the node of all the prediction of each decision tree on reling on the “Majority of wins” model uses the risk of error from the individual tree.
4. Neural Network:
It is a multilayer neuron inspired by human brain.

Layer 1 : Input Layer
Layer 2 : Hidden Layer
Layer 3 : Hidden Layer
Layer 4 : Output Layer
Each node in a hidden layer represent the function that input goes to, utlimately reading the output in the green cicle that is output layer[L4].
The output of the Classification Model is discrete.
The most important model of the classification model is Logistic Regression
- Logistic Regression:
Logistic Regression is similar to linear regression but, it used to model the probability of finite number of outcomes.
The output value can appear between 0 and 1.
2. Support Vector Machine:

It is supervised classified technique that carries an objective to find the hyperplane in N-Dimensional space that distinctly classifies the data points.
3. Naive Bayes:

Classifier that act as a probabilistic machine learning model, used for classification task .The crux of the classification is based on neural based theorem.
Unsupervised Learning is used to draw inference and find the patterns from input data without reference to the labeled outcomes
Two main Methods used in Unsupervised Machine learning includes
- Clustering
- Dimensionality reduction
clustering involves grouping of data points. It is frequently used for customer segmentation, fraud detection and document classification.
Common clustering technique includes:
A. K-Means
B. Hierarchical
These technique has different methods in finding clusters they all aim to achieve the same thing
It is a process of reducing dimensions of your features set auto states simply reducing the number of features most dimensionality reduction technique.
Dimensionality reduction technique can be categorized on either features elimination or feature extraction.
A popular dimensionality reduction technique is called principle component analysis or PCA





