
Firstly, let me clarify what I mean by ‘design’. Design, in the context of this talk, is the process of creating a useful, usable and safe product or service, by making thoughtful decisions that have the end-user experience at the center.
There is no shortage of information out there educating designers on the fundamentals of machine learning. Most typically they focus on the different methods of training a model — supervised, un-supervised, semi-supervised etc. This is good information that feeds into the ideation phase of the design process.
However, for the next generation of products and services leveraging AI, to truly make a meaningful impact on our lives, design needs to understand and contribute to the entire ML development cycle.

The typical design and engineering engagement model involves design coming up with an idea or concept, and iterating on that until we reach a solution that we can hand off to the engineering team to build.

Design then enters back into the conversation towards the end of the development process to make any adjustments based on technical feasibility, user test, visual QA etc.
In this world, design doesn’t typically get into the weeds of each and every technical decision. Angular versus Lit? Server vs client? These are primarily engineering decisions that have little impact on the end user.
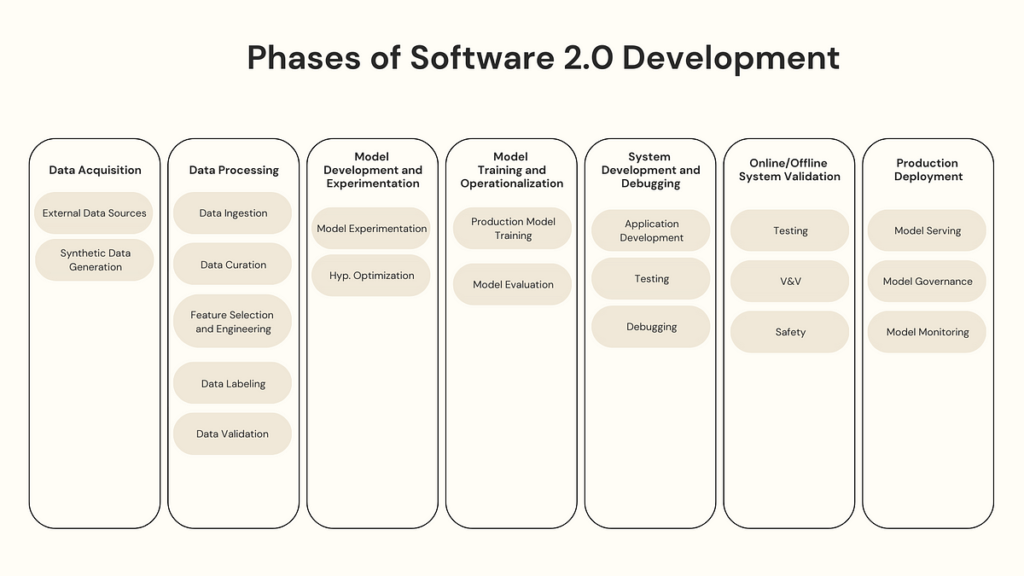
This is very different in the development process of products and services that are powered by AI. We call this the Software 2.0 development cycle.

The term Software 2.0 was coined by Andrej Karpathy in 2017 and it explains the difference between the development process of classical software versus ML software.
“The “classical stack” of Software 1.0 is what we’re all familiar with — it is written in languages such as Python, C++, etc. It consists of explicit instructions to the computer written by a programmer. By writing each line of code, the programmer identifies a specific point in program space with some desirable behavior.” Source
In software 1.0, code drives the development of the application — if needed, one can inspect the code to understand the logic behind decisions that have been made and make change retrospectively pretty easily. In contrast in software 2.0 its data that drives the development of the application. And the models produced from this data, will not give you any insights into the logic behind decisions that have been made along the way.
“In contrast, Software 2.0 is written in much more abstract, human unfriendly language, such as the weights of a neural network. No human is involved in writing this code because there are a lot of weights (typical networks might have millions), and coding directly in weights is kind of hard” Source
In the software 2.0 development cycle, each stage is a juncture where important decisions are being made that have a dramatic impact on the end user. It’s imperative, if we are to successfully build the next generation of useful, usable and safe applications of AI, that these decisions are made with the end user at the center. That these decisions are designed.
If we take a more in-depth look at the process involved in developing a machine learning model, we can see it’s very complex — and while there are many points within this process that deserve designer engagement, today I will highlight just 3.


Data defines a large part of the outcome of an ML model. You’ve probably heard of ‘garbage in, garbage out’. But there is a particular stage within the data processing pipeline that has a large impact on the end user experience — it’s called ‘feature selection’.

To train a model, we collect enormous amounts of data to help the machine learn better. Usually, a large portion of the data collected is noise, and some might not contribute to the training of our model. The model may also learn from irrelevant data in the dataset and become inaccurate. Feature selection is the process of defining what attributes of your data you will use to train your model.
So why is this important for design?
Consider this example:

A few years ago in 2019, Apple and Goldman Sachs were accused of creating an ML powered credit card application algorithm for the Apple Card that was sexist. Users, including Steve Wosniak, noticed that it was offering smaller lines of credit to women than to men, even though from a credit worthiness perspective they were relatively the same.
According to Valerie Carey, the speculation of reasons tended to fall into 2 major categories:
Women have lower income because of workplace discrimination, and credit limits are linked to income; therefore, women are assigned lower limits.
The Apple Card algorithm’s training data contained information about shopping patterns, which were a proxy for gender, and led to stereotyping of female applicants. Source
Let’s look at an example…

If we look at this data, we can assume that the ground truth data was primarily dependent on the annual income.

But the training data used to train this model had additional features added — they added spending patterns.

So we know the ground truth had already been added given the annual income — so annual income = lower limit.

But unfortunately the model learned that instead of annual income being the major factor, spending patterns were. And we can see from this data that, even though the total spending per month was the same, there were particular patterns in the categories of spending that inferred whether a data point was either male or female.

So the spending patterns features became a proxy for gender, so from the models perspective we can just assume that the spending pattern were a gender feature.

So now when we look at unseen data, we can see that annual income is high, however the spending patterns are representative of someone who is female. And because of this, the predicted credit limit is low.
There are a few statistical ways, called ‘fairness metrics’, of choosing features to reduce the likelihood of issues like this, but as stated by Valerie Carey in her article Feature Choice and Fairness: Less May Be More, these are not always effective.
Feature selection needs human judgment and more specifically, needs to involve a designer who can extrapolate the impact of certain feature choices, to the impact on the end user (and society!)
Now going back to designs focus — creating useful, usable and safe products with the user at the center.
Useful
If we ask ourselves about usefulness — will including or excluding certain features, effect the intended purpose of the product or service?
If we ask ourselves about usefulness — Will including or excluding certain features, effect the intended purpose of the product or service?
Usable
Will including or excluding certain features, impact whether a user is willing or able to use the product?
You can assume that if we were to continue to use the spending habits feature, that a large part of our user base — females — may not want to use our product.
Safe
Do any of the features contain information about a protected group — explicitly or by proxy? How does including these features impact the end user?
Well we know in the Apple Credit Card case, that it actually ended up discriminating against an entire gender and perpetuating an existing societal bias.

Now moving along in the development process, we get to ‘Model Development and Experimentation’. This is where we make choices on things like the model architecture, hyperparameters, training datasets and evaluation metrics. ML engineers experiment with different combinations of these things until they find the combination that produces the best model that then can be promoted to be ‘productionized’ and scaled up.
Now if you are up-to-date with the latest design/AI blogs I mentioned before, you would be familiar with reinforcement learning.

In reinforcement learning (RL), training a model consists of two stages: First, the programmer defines the objective; then an optimisation algorithm tries to find the best possible solution based on the reward function.

Imagine if you were training your dog to compete in an agility competition with the following course:

If I only set the objective to ‘complete the circuit in the least amount of time’ and only reward the dog at the end of the circuit, it may learn that the best way to achieve that goal is to ignore all the agility obstacles and run right to the finish line.

This is an example of where the objective’s definition may not accurately capture the human’s intention. This is called a “misaligned” objective/reward function. Source
Now if I update the objective to “complete each obstacle, in order, without faults, in the least amount of time” we are much more likely to get the result we are looking for.

Designers need to understand, and actively contribute to, the way a machine learning model learns to make sure the objective/reward function is aligned with the intended user outcome.
Useful
Looking at design again — is it useful? By choosing a specific objective and reward function, will the product still provide value to the user? Are we solving the right problem?
In the case of our show dog — we can see that by setting the objective function to just speed, the dog would not be very useful for me to collect the competition prize.
Usable
Can a user interact with the product or service given the objective function chosen?

Hypothetically, if a robotic arm that was built to assist in remote surgeries, was trained on the objective to perform E2E surgery at the highest precision — but when deployed the movement of the robotic arm was too fast or completed the steps in a nonsensical order, making it impossible for the surgeon to take control — this would not be usable.
Safe
Will the learned behavior from the objective function, put anyone in harms way?
The classic example of this is the paperclip maximizer theory, where philosophers have speculated that an AI tasked with creating paperclips might cause an apocalypse by learning to divert ever-increasing resources to the task, and then learning how to resist our attempts to turn it off.

Let’s now skip to ‘System Development and Debugging’. In theory, we now have a robust model that doesn’t introduce unintended bias, and performs as designed. The next step in to now embed that model into some sort of application that delivers the predictions to the end user.
This is probably the most obvious place where design is integral — but again, there are some technical details that are needed to be ‘designed’.

In a classification task, when a model makes a prediction — the accuracy is determined by assessing whether the prediction is either a ‘True Positive’, ‘True Negative’, ‘False Positive’ or a ‘False Negative’. There are many metrics you can use to asses the performance of a model — but today I am going to focus on the concepts of precision and recall.
Precision is ‘what proportion of positive identifications was actually correct?’ and recall is ‘what proportion of actual positives was identified correctly?’.
Here is an example….Imagine we’ve just trained a model to identify whether a patient is having a heart attack.

Our model made 15 total predictions of whether a patient is having a heart attack or not.

The number of times the model PREDICTED that the patient WAS having a heart attack is 10. But was only right in 6 cases, so our precision is 6 out of 10: 60%.

Now the number of times the patient was ACTUALLY WAS having a heart attack is 9. And the amount of times the model was able to get it right was 6, so our recall is 6 out of 9 = 67%.
The important thing to know is there is an inverse relationship between precision and recall. You can only optimize for one.

By optimizing for precision you are serving less predictions, but highly likely to be correct. And by optimizing for recall, you are serving more predictions, but less likely to all be correct.
Each time we create a product or service that uses classification, design must assess the impact of the precision/recall tradeoff on the end user experience so the right optimization can be made.
Useful
If you are optimizing for precision, and only display a reduced amount of results — will the product still be useful?
If you were developing an AI stylist, but the product only ever returned 1 option — would this be useful?
Usable
On the other hand, if you were to optimize for recall, would the large quantities of results at varying degrees of confidence make the product non-usable?
If it is best to focus on high recall — can we consider design techniques such as progressive disclosure to make sure the product does not cause cognitive overload?
Safe
What happens to the user if you display a False Positive or a False Negative?
We need to understand the impact of showing false results and decide whether the harm done by showing a False Negative outweighs the harm done by providing a False Positive.
Is it better to treat a patient who is not having a heart attack, versus not treating a patient who is?





