
We all know that AI is revolutionizing various aspects of our lives, from healthcare to finance to transportation. One remarkable subfield of AI that has gained significant attention and sparked fascination is generative AI.
First of all let us understand what generative AI is.
On one hand we have traditional ML models are used to perform specific tasks and on the other hand are generative AI models that generate original content on their own without much human intervention. These models are trained on vast amounts of data and learn patterns, styles, and structures to generate new content that is coherent and relevant.
Generative AI is still a relatively new field, but it has the potential to revolutionize the way we create and consume content. As the technology continues to develop, we can expect to see even more innovative and creative applications of generative AI in the future.
Generative AI has several types of models. Traditional approaches include VAEs, GANs etc. But recently a new approach has surfaced and is taking this world of generative AI to itself. Stable Diffusion.
Stable Diffusion was first released in 2022 and is widely being used to generate aesthetic and detailed images based to textual prompts but it can also do other tasks like inpainting (filling missing parts), outpainting (extending images), and image-to-image generations.
Let us understand how these models work.
These models approach the task of generating content in a different perspective. These models focus on a diffusion process that gradually evolves a noise vector to resemble the target data distribution.
Woah! This sounds confusing. Lets break it down in simpler terms.
Imagine you have a blank canvas and you want to create a beautiful painting on it. However, instead of starting with a brush and paint directly, you decide to take a different approach. You begin with a random pattern on the canvas, which represents a noisy starting point (the noise vector).
Now, instead of painting the final image all at once, you decide to make small, controlled changes to the pattern over multiple steps. At each step, you carefully analyze the current pattern and make adjustments to bring it closer to your desired painting (target data distribution). You might add or remove small brushstrokes, adjust colors, or change the overall composition.
As you progress through each step, the pattern gradually evolves becoming more refined and closer to the intended output painting. You repeat this process multiple times, each time refining the pattern further until you achieve your final desired result.
So diffusion models follows a similar process. The random noise vector represents the initial pattern, and each step in the diffusion process corresponds to refining the noise vector. The model learns to make small adjustments to the noise vector at each step, gradually transforming it to generate a high-quality sample that resembles the target data distribution.
This whole process is termed as diffusion process. Stable diffusion has a similar approach but it works by gradually adding noise to an image while also keeping the image’s overall structure intact. This process is called stabilization, and it is what gives stable diffusion models their name.
The main difference between stable diffusion and normal diffusion is that stable diffusion is more likely to produce images that are both realistic and coherent. This is because the stabilization process helps to prevent the image from becoming too noisy or distorted.
Another difference between stable diffusion and normal diffusion is that stable diffusion is typically slower than normal diffusion. This is because the stabilization process requires more computation.
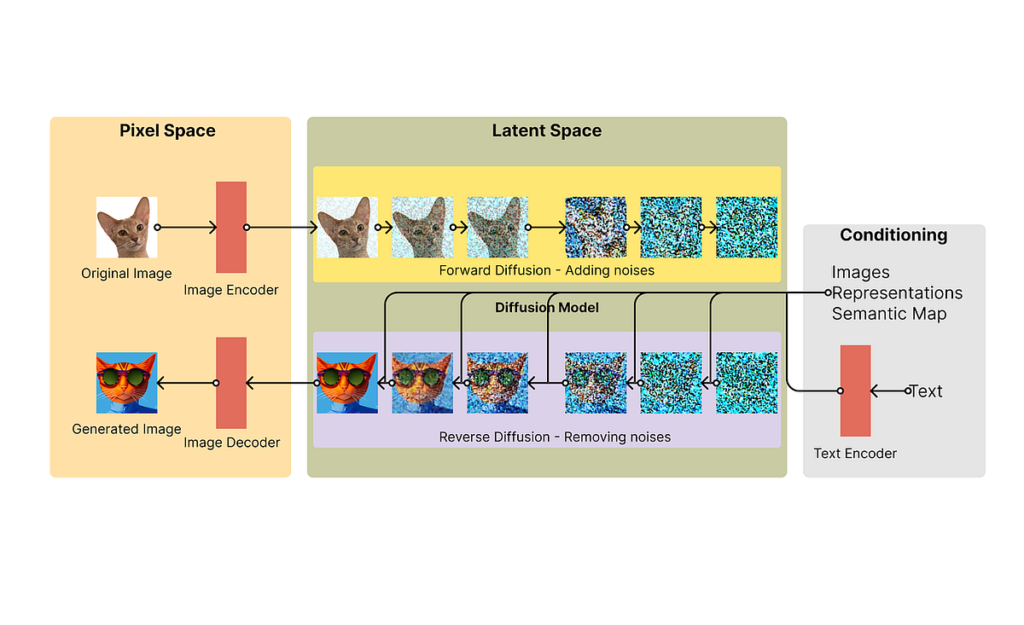
Stable Diffusion uses a kind of diffusion model called latent diffusion model (LDM). It consists of three parts: the variational autoencoder (VAE), U-Net and an optional text encoder. First of all the VAE encodes the image from pixel form into latent space and gaussian noise is applied iteratively in this representation using diffusion process. U-Net denoises the output and finally the decoder generated the final image in pixel form.

This image sums up the complete process of stable diffusion. We can see that we have two spaces: pixel space and latent space. The encoding and decoding is done via the variational autoencoder and decoder and in the latent space, forward diffusion process is followed as explained above.
Hope this article helped! Cheers!





