
Introduction
In machine learning, the concept of independent and identically distributed (IID) plays a critical role in various aspects of data analysis, model training, and evaluation. IID assumptions are fundamental in ensuring the reliability and validity of many machine learning algorithms and statistical techniques. This essay explores the significance of IID in machine learning, its assumptions, and its implications on model development and performance.
Understanding IID in Machine Learning
In the context of machine learning, IID refers to the assumption that the training data used to build a model are independently and randomly sampled from the same underlying distribution. Each data point is assumed to be independent of others and follows the same distributional characteristics. This assumption enables the application of powerful statistical methods and learning algorithms that rely on the absence of systematic dependencies or biases within the data.
Assumptions of IID in Machine Learning
- Independence: The independence assumption implies that the occurrence or value of one data point does not provide any information about the occurrence or value of another data point. It assumes that the data points are not influenced by each other and that there is no hidden structure or correlation among them. Violations of this assumption can lead to biased or unreliable model predictions.
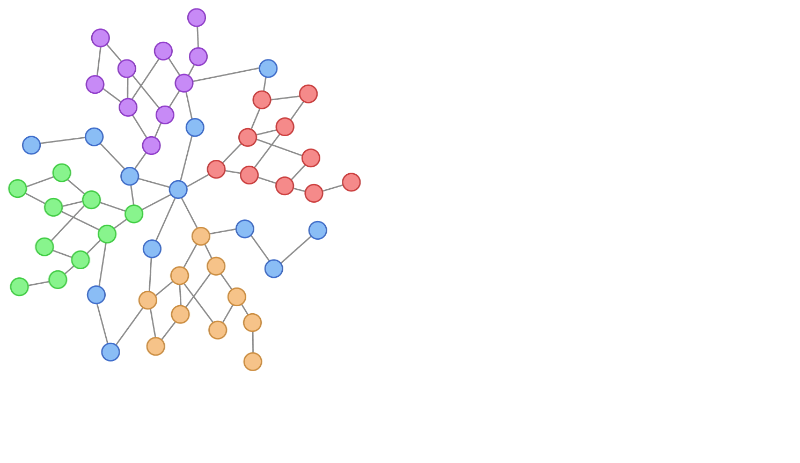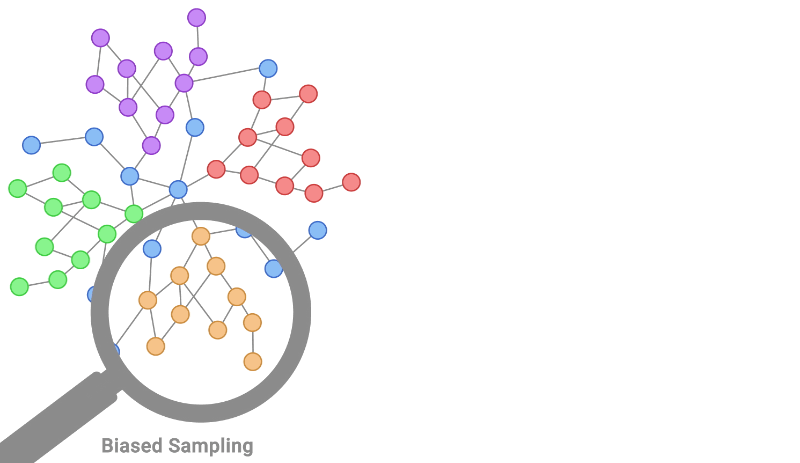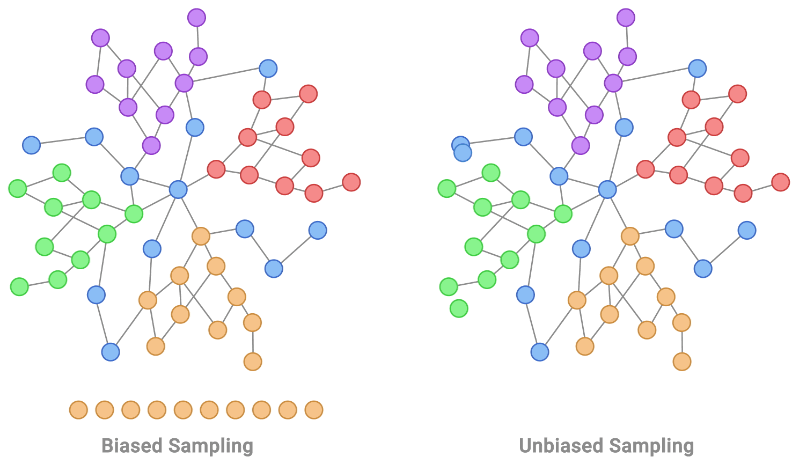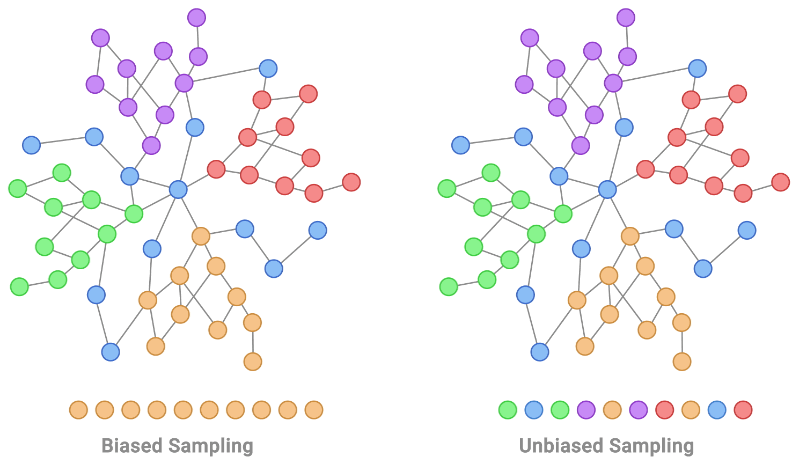
- Identical Distribution: The identical distribution assumption assumes that the data points are drawn from the same underlying distribution. It implies that the statistical properties, such as mean, variance, and other distributional characteristics, remain consistent across the entire dataset. Deviations from this assumption can introduce sampling bias, causing models to generalize poorly to new, unseen data.
Implications of IID in Machine Learning
- Training and Evaluation: IID assumptions are crucial during model training and evaluation. When the training data satisfies the IID assumption, machine learning algorithms can effectively learn the underlying patterns and make accurate predictions. Additionally, during model evaluation, IID allows for the use of cross-validation techniques and statistical tests, ensuring that the performance estimates are reliable and representative of the model’s true performance.
- Feature Selection and Engineering: The IID assumption influences feature selection and engineering processes. If the independence assumption is violated, it is essential to identify and handle correlated or dependent features properly. Feature selection methods can help identify redundant or highly correlated features, while feature engineering techniques can transform or combine features to mitigate the impact of dependencies within the data.
- Regularization and Overfitting: IID assumptions are closely tied to the problem of overfitting. When the data violates the IID assumption, models may tend to memorize or overfit to the specific patterns present in the training data, failing to generalize well to unseen data. Regularization techniques, such as L1 or L2 regularization, can help mitigate overfitting and improve the generalization performance of models.
- Statistical Inference and Hypothesis Testing: IID assumptions are critical in statistical inference and hypothesis testing within machine learning. Statistical tests, such as t-tests or chi-square tests, assume that the data points are independently and identically distributed. Violations of the IID assumption can lead to inaccurate p-values, affecting the validity of statistical inferences and hypothesis testing results.
Challenges and Considerations
It is essential to recognize that the IID assumption may not hold in all real-world scenarios. Real-world datasets often exhibit complex dependencies, temporal correlations, or imbalanced distributions. When dealing with non-IID data, specialized techniques, such as time series analysis, sequence modeling, or techniques for handling imbalanced data, need to be employed to address these challenges appropriately.
In machine learning, the concept of independent and identically distributed (IID) is often assumed for the training and evaluation of models. While the data may not always strictly adhere to the IID assumption, it is a common starting point for many algorithms. Here’s an example of how you can create an IID dataset and train a simple machine learning model using Python:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# Generate IID dataset
np.random.seed(0)
num_samples = 1000
num_features = 5
# Generate independent random features
X = np.random.rand(num_samples, num_features)
# Generate independent and identically distributed labels
y = np.random.randint(0, 2, num_samples)
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
In the above code, we start by generating an IID dataset. We use np.random.rand to create independent random features (X) where each row represents a sample, and each column represents a feature. We also generate independent and identically distributed labels (y) using np.random.randint, where each label corresponds to a sample.
Next, we split the data into training and testing sets using train_test_split from the scikit-learn library. The training set (X_train and y_train) will be used to train the model, while the testing set (X_test and y_test) will be used to evaluate the model’s performance. We then initialize a logistic regression model using LogisticRegression from scikit-learn and fit it to the training data using fit. After training, we make predictions on the test set using predict. Finally, we calculate the accuracy of the model’s predictions using accuracy_score from scikit-learn and print the result.
Keep in mind that this example assumes a simplified scenario where the data is IID. In practice, real-world datasets often exhibit more complex patterns, dependencies, or imbalances, requiring additional preprocessing steps and specialized techniques to handle such situations.
Conclusion
The concept of independent and identically distributed (IID) plays a crucial role in machine learning, enabling the development of robust models and accurate predictions. The assumption of independence and identical distribution provides a foundation for statistical methods, regularization techniques, and model evaluation procedures. Understanding the implications of IID assumptions helps machine learning practitioners make informed decisions about data preprocessing, algorithm selection, and model evaluation to ensure the reliability and generalization capabilities of their models.





